DevMine
A set of projects, combined together, make DevMine possible. Each of them has its own purpose and as such, the project is very modular.
Most of the projects are implemented in the Go programming language. An early prototype as well as the first version of DevMine were written in Python but all of this code base is now obsolete. DevMine uses PostgreSQL as its database system and this component is essential to glue all sub-projects together.
Current implementation of the DevMine project consists of 11 sub-projects:
- crawld: is responsible for collecting metadata about developers as well as cloning source code repositories.
- ght2dm: is a tool to import GHTorrent project BSON dumps into the DevMine database.
- parsers: are responsible for parsing source code and producing an abstract representation of it, in JSON.
- srccat: can create large tar archives from source code repositories to make them suitable for processing on Hadoop or Spark.
- srctool: is a tool to manage language parsers. It can install them and run them on source code.
- repotool: aggregates source code repositories metadata from version control systems (Git, Mercurial, …) and produces and abstract representation of it, in JSON.
- srcanlzr: analyzes source code, from the abstract representation produced by the various language parsers.
- fluxio: a tool for JSON/PostgreSQL-jsonb I/Os
- featscomp: computes features from all of the collected metadata and stores them into the database.
- API-server: serves all data produced by the tools mentioned above in the form of a JSON RESTful API.
- webapp: is a demo web interface that interacts with the API-server.
Source analysis toolchain architecture
The tools from the source analysis toolchain work much like standard UNIX tools in the sense that, generally speaking:
- One tool does one thing.
- JSON input and output of the tools are pipeable to each another.
A schema is probably better at explaining that so here is one:
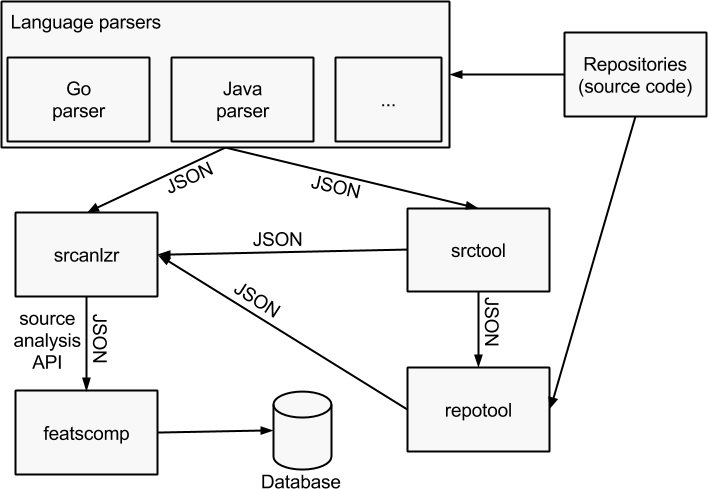
From the schema, you can deduce that you may omit using some of the tools when running the analysis. However, using all of the tools leads to the most complete source analysis API output.
Out of the source analysis API output, we are able to compute features with
featscomp and insert the results into the database. However, srcanlzr does a
good job at providing part of the features since it computes things such as the
cyclomatic complexity (McCabe) over the source code or counts the lines of code
for each projects for instance.
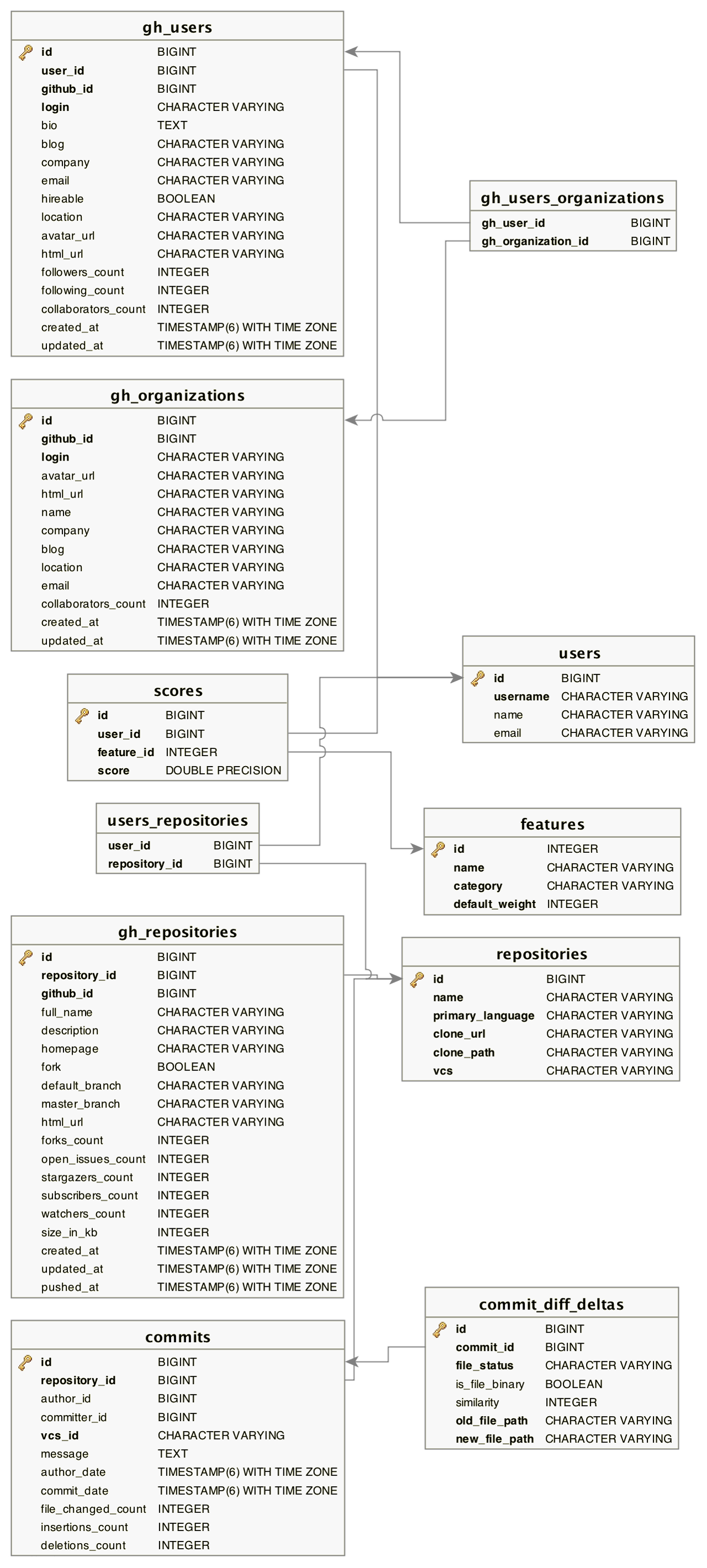
Database schema
The PostgreSQL database is used by crawld, repotool, featscomp and api-server.