crawld: a data crawler and repositories fetcher


![]()
crawld is a metadata crawler and source code repository fetcher.
Hence, crawld comprises two different parts: the crawlers and the fetcher.
Crawlers
crawld focuses on crawling repositories metadata and those of the users
that contributed, or are directly related, to the repositories from code
sharing platforms such as GitHub.
Only a GitHub crawler is currently implemented.
However, the architecture of crawld has been designed in a way such that new
crawlers (for instance a BitBucket crawler) can be
added without hassle.
All of the collected metadata is stored into a
PostgreSQL database. As crawld is designed to
be able to crawl several code sharing platforms, common information is stored
in two tables: users and repositories. For the rest of the information,
specific tables are created (gh_repositories, gh_users and
gh_organizations for now) and relations are established with the users and
repositories tables.
The table below gives information about what is collected. Bear in mind that some information might be incomplete (for instance, if a user does not provide any company information).
| Repository | GitHub Repository | User | GitHub User | GitHub Organization |
|---|---|---|---|---|
| Name | GitHub ID | Username | GitHub ID | GitHub ID |
| Primary language | Full name | Name | Login | Login |
| Clone URL | Description | Bio | Avatar URL | |
| Homepage | Blog | HTML URL | ||
| Fork | Company | Name | ||
| Default branch | Company | |||
| Master branch | Hireable | Blog | ||
| HTML URL | Location | Location | ||
| Forks count | Avatar URL | |||
| Open issues count | HTML URL | Collaborators count | ||
| Stargazers count | Followers count | Creation date | ||
| Subscribers count | Following count | Update date | ||
| Watchers count | Collaborators count | |||
| Size | Creation date | |||
| Creation date | Update date | |||
| Update date | ||||
| Last push date |
Fetcher
Aside from crawling metadata, crawld is able to clone and update
repositories, using their clone URL stored into the database.
Cloning and updating can be done regardless of the source code management
system in use (git,
mercurial,
svn, …), however only a git fetcher is
currently implemented.
As source code repositories usually contain a lot of files, crawld has an
option that allows storing source code repositories as tar archives which makes
things easier for the file system shall you clone a huge number of
repositories.
Installation
crawld uses git2go, a ligit2 Go binding for its git operations. Hence,
libgit2 needs to be installed on your system unless you statically compile it
with the git2go package.
To install crawld, run this command in a terminal, assuming
Go is installed:
go get github.com/DevMine/crawld
Or you can download a binary for your platform from the DevMine project’s downloads page.
You also need to setup a PostgreSQL database.
Look at the
README file
in the db sub-folder for details.
Usage and configuration
Copy crawld.conf.sample to crawld.conf and edit it according to your
needs. The configuration file has several sections:
- database: allows you to configure access to your PostgreSQL
database.
- hostname: hostname of the machine.
- port: PostgreSQL port.
- username: PostgreSQL user that has access to the database.
- password: password of the database user.
- dbname: database name.
- ssl_mode: takes any of these 4 values: “disable”, “require”, “verify-ca”, “verify-null”. Refer to PostgreSQL documentation for details.
- clone_dir: specify where you would like to clone the repositories.
- crawling_time_interval: specify the waiting time between 2 full crawling periods. This is irrelevant for the crawlers where no limit is specified.
- fetch_time_interval: specify the waiting time between 2 full repositories cloning/updating periods. You shall preferably choose a small time period here since the repositories fetcher cannot usually keep up with the crawlers and you likely want it to update/clone the repositories continuously.
- fetch_languages: specify the list of languages the fetcher shall restrict to. If left empty, all languages are considered.
- tar_repositories: a boolean value indicating whether the repositories shall be stored as tar archives or not.
- tmp_dir: specify a temporary working directory. If left empty, the default temporary directory will be used. This directory is used on clone and update operations when the tar_repositories option is activated. It is recommended to use a ramdisk for increased performance.
- tmp_dir_file_size_limit: specify the maximum size in GB of an object to be temporarily placed in tmp_dir for processing. Files of size larger than this value will not be processed in tmp_dir.
- max_fetcher_workers: specify the maximum number of workers to use for the fetching task. It defaults to 1 but if your machine has good I/O throughput and a good CPU, you probably want to increase this conservative value for performance reasons. Note that fetching is I/O and networked bound more than CPU bound and hence you probably do not want to increase this value too much.
- throttler_wait_time: indicates how much time to wait, in seconds, before resuming normal operation after throttling.
- throttler_sliding_window_size: represents the size of the sliding window used by the error rate throttler. If you have no idea about what that means, it is safe to omit it since default value shall be sane.
- throttler_leak_interval: specify the time to wait, in milliseconds, before taking off a unit from the sliding window. Again, if you have no idea about what that means, it is safe to omit it since default value shall be sane.
- crawlers: allows you to configure options for the crawlers.
- type: specify crawler type. Currently, only “github” is implemented.
- languages: list of programming languages of the repositories you are interested into. All languages used in a repository are considered and not only the primary language.
- limit: set this value to 0 to not use a limit. Otherwise, crawling will stop when “limit” repositories have been fetched. Note that the behavior is slightly different whether you use the search API or not. When you use the search API, this limit correspond to the number of repositories to crawl per language listed in “languages” . When you do not use the search API, this is a global limit, regardless of the language.
- since_id: corresponds to the repository ID (eg: GitHub repository ID in the case of the github crawler) from which to start querying repositories. Note that this value is ignored when using the search API.
- fork: skip fork repositories if set to false.
- oauth_access_token: your API token. If not provided,
crawldwill work but the number of API call is usually limited to a low number. For instance, in the case of the GitHub crawler, unauthenticated requests are limited to 60 per hour where authenticated requests goes up to 5000 per hour. - use_search_api: specify whether you want to use the search API or not. Bear in mind that results returned via the search API are usually limited so you probably not want this option set to true usually. In the case of the GitHub crawler, when set to true, the limit is 1000 results per search. This means that you will get at most the 1000 most popular projects (in terms of stars count) per language listed in “languages”.
Once the configuration file has been adjusted, you are ready to run crawld.
You need to specify the path to the configuration file with the help of the -c
option. Example:
crawld -c crawld.conf
Some command line options are also available, mainly where to store log files
and whether to disable the data crawlers or repositories fetcher (by default,
the crawlers and the fetcher run in parallel). See crawld -h for more
information.
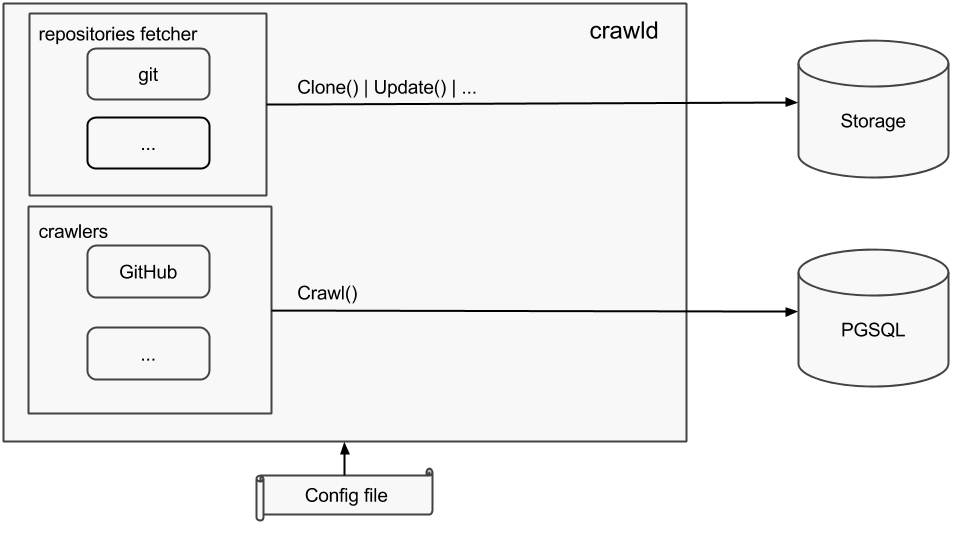
Internals
crawld consists of two main parts internally: the crawlers (only GitHub for
now) and the repositories fetcher (which only supports git for now).
The metadata crawled are put into the database whereas the repositories are cloned on physical storage.
Note that the internal architecture of crawld has been thought to make it easy
to implement new crawlers or VCS backends.